응용층은 사용자에게 서비스를 제공하며 통신은 논리적 연결을 사용하여 제공한다.
서비스 제공
표준과 비표준 프로토콜
인터넷의 원활한 동작을 제공하기 위해 TCP/IP 프로토콜의 처음 네 계층에서 사용되는 프로토콜들은 표준화되고 문서화되어야 함
보통 이 프로토콜들은 윈도우나 유닉스와 같은 운영체제에 포함되는 패키지의 일부로 포함되지만, 보다 더 융통성이 있기 위해서는 응용층 프로토콜들은 표준화와 비표준화 둘 다 될 수 있음
| 1. 표준 응용층 프로토콜 - 인터넷 관리기관에 의해 표준화되고 문서화된 여러 응용층 프로토콜이 있으며 오늘날 매일 인터넷과 대화하며 이 프로토콜을 사용하고 있음 - 각 표준 프로토콜은 사용자에게 특정한 서비스를 제공하기 위해 사용자 및 전송층과 상호 작용하는 한 쌍의 컴퓨터 프로그램임 2. 비표준 응용층 프로토콜 - 만약 프로그래머가 전송층과 상호 작용을 하여 사용자에게 서비스를 제공하는 2개(송신-수신)의 프로그램을 작성할 수 있으면 비표준 응용층 프로토콜을 제작하는 것이 가능 - 사적으로 사용하는 경우, 인터넷 관리기관의 승인이 필요하지 않은 비표준(독자적인) 프로토컬의 생성은 인터넷을 전 세계적으로 인기 있게 만들었음 - 개인 기업은 표준 응용 프로그램을 전혀 사용하지 않고도 TCP/IP 프로토콜의 처음 네 프로토콜이 제공하는 서비스를 사용하여 전 세계에 있는 사무실들과 통신할 수 있는 새로운 맞춤형 응용 프로토콜을 만들 수 있음 - 이를 위해 필요한 것은 전송층 프로토콜에서 제공되는 가용한 서비스를 이용하여 컴퓨터 언어를 사용해 프로그램을 작성하는 것 |
응용층 패러다임
인터넷을 이용하기 위해서는 서로 상호작용하는 2개의 응용 프로그램이 필요
| Traditional Paradigm: 클라이언트-서버 패러다임 - 서버 프로세스: 항상 실행 - 클라이언트 프로세스: 서비스 필요 시 시작 - ex) WWW, HTTP, FTP, SSH, E-mail New Paradigm: 대등-대-대등 패러다임 - Peer-to-Peer Paradigm - 동등한 대등들로 구성 - 이 패러다임에서는 서버 프로세스가 항상 실행 중이고 클라이언트 프로세스가 연결될 때까지 기다릴 필요가 없음 - 책임은 동료간에 공유됨 |
WWW(World Wide Web)
웹(Web)의 개념은 유럽원자핵공동연구소(CERN)에 근무하던 팀 버너스리(Tim Bermers-Lee)가 유럽 내의 다른 장소에 있는 연구자들이 서로의 연구에 접근할 수 있도록 하기 위해 1989년 처음 제안하였고, 상업적인 웹은 1990년대 초반에 시작됨
오늘날 웹은 웹 페이지(web page)라 불리는 문서들로 되어 있는 정보의 보고
웹 페이지는 전 세계에 광범위하게 분포되어 있고 서로 연관된 문서끼리 링크되어 있음
웹의 인기와 성장은 분산(distribute)과 링크(link)라는 2개의 용어와 연관
| 분산 분산은 웹의 성장을 가능하게 하였는데, 전 세계 각각의 웹 서버는 새로운 웹 페이지를 저장소에 보관하고 어떠한 서버의 과부하 없이 모든 인터넷 사용자들에게 알릴 수 있음
링크 링크는 하나의 웹 페이지가 전 세계 어느 곳에 다른 서버가 있더라도 이 서버에 저장된 다른 웹 페이지를 참조할 수 있도록 하였음
|
월드 와이드 웹 구조
- 오늘날 WWW는 분산 클라이언트/서버 서비스임
즉, 브라우저를 사용하는 클라이언트가 서버를 사용하여 서비스에 접근할 수 있지만, 제공되는 서비스는 사이트(site)라고 불리는 여러 장소에 분산되어 있음
- 각 사이트는 하나 이상의 웹 페이지를 소유하고, 각 웹 페이지는 동일한 사이트 또는 다른 사이트에 있는 다른 페이지로 연결할 수 있는 링크를 포함할 수 있음
웹 클라이언트(브라우저)
다양한 벤더들이 웹 페이지를 해석하여 표현하는 상용 브라우저를 제공하며, 이들은 모드 거의 동일한 구조를 사용

보통 브라우저는
1. 제어기
2. 클라이언트 프로토콜
3. 해석기
부분으로 구성
|
- 제어기는 키보드나 마우스로부터 입력을 받아 클라이언트 프로그램을 사용하여 문서에 접속
- 문서에 접속한 후 제어기는 해석기 중 하나를 사용하여 문서를 화면에 나타냄 - 클라이언트 프로토콜은 FTP나 HTTP와 같은 다음에 설명할 프로토콜 중의 하나가 될 수 있음 - 해석기는 문서의 유형에 따라 HTML, 자바(JAVA) 또는 자바 스크립트(JavaScript)가 될 수 있음 - 상업적인 브라우저에는 인터넷 익스플로러(에지), 파이어폭스, 크롬등 |
웹 서버
- 웹페이지는 서버에 저장
자원 위치 지정자(URL, Uniform Resource Locator)
- 파일로서 웹 페이지는 다른 웹 페이지와 구별되는 유일한 식별자를 가져야 함
| Protocol : 첫 번째 식별자는 웹 페이지에 접근하는데 필요한 클라이언트-서버 프로그램의 약어 - 대부분 HTTP(HyperText Transfer Protocol)을 사용하지만, FTP(File Transfer Protocol) 같은 다른 프로토콜을 사용할 수 있음
Host : 호스트 식별자는 서버의 IP 주소일 수도 있고, 서버에 주어진 유일한 이름일 수도 있음 Port : 16비트 정수형인 포트는 보통 클라이언트-서버 응용을 위해 미리 정의되어 있음 - 예를 들어 만약 HTTP 프로토콜이 웹 페이지의 접근을 위해 사용된다면, 잘 알려진 포트 번호는 80번이지만, 다른 포트가 사용된다면 그 번호는 명시적으로 주어질 수 있음
Path : 경로는 하위 운영체제에서 파일의 위치와 이름을 식별 - 이 식별자의 형태는 보통 운영체제에 의해 결정
- 유닉스의 경우, 경로는 파일 이름이 따라오는 디렉토리 이름의 집합이고 이것은 슬래시(/)로 구별
(이 4개의 조각을 조합하기 위해 자원 위치 지정자(URL, uniform resource locator)가 고안되었다.) |
웹 문서
WWW 상의 문서는 정적, 동적, 액티브라는 세 분류로 크게 구분
| 정적 문서 - 정적 문서(static document)는 서버에서 생성/저장된 고정-내용(fixed-content) 문서
- 클라이언트는 오직 문서의 복사본을 얻을 수 있음
- 물론 서버에 있는 내용이 변경될 수 있으나, 사용자가 이를 바꿀 수는 없음
- 클라이언트가 문서를 액세스할 때, 문서의 복사본이 전송되며, 그 후 사용자는 브라우저 프로그램을 통해 문서를 볼 수 있음
- 정적 문서는 다음의 언어 중 하나를 사용하여 만들어짐(HTML(Hyper Text Markup Language), XML(Extensible Markup Language), XSL(Extensible Style Language) 그리고 XHTML(Extensible Hypertext Markup Language)) |
| 동적 문서 - 브라우저가 문서를 요청할 때마다 웹 서버에 의해 생성
- 요청이 들어오면, 웹 서버는 동적 문서를 만드는 응용 프로그램이나 스크립트를 실행하고, 서버는 프로그램 또는 스크립트의 출력을 그 문서를 요청한 브라우저에게 응답으로 반환 - 각 요청에 대해서 새로운 문서가 생성되기 때문에 동적 문서의 내용은 각각의 요청마다 달라질 수 있음 - 동적 문서의 매우 간단한 예는 서버로부터 날짜와 시간을 받는 것으로, 날짜와 시간은 매 순간마다 변경되므로 동적인 정보의 일종임 - 클라이언트는 서버가 UNIX의 date와 같은 프로그램을 수행한 후 그 프로그램의 결과를 클라이언트에게 전송하도록 요청할 수 있음 |
| 액티브 문서 - 많은 응용에서 클라이언트 사이트에서 수행될 프로그램이나 스크립트를 필요로 하며, 이들을 액티브 문서(active document)라 함
- 예를 들어, 화면에서 움직이는 그림들을 생성하거나 사용자와 상호작용을 하는 프로그램을 수행시키길 원한다고 가정해 보면 프로그램은 애니메이션이나 상호작용이 발생한 클라이언트에서 반드시 실행되어야 하고, 브라우저가 액티브 문서를 요구할 때, 서버는 문서의 복사본이나 스크립트를 전송하게 되고 문서는 클라이언트(브라우저)에서 실행 - 액티브 문서를 만드는 방법 중 하나는 서버에서 자바로 작성된 프로그램인 자바 애플릿(Java applet)을 사용하는 것 - 다른 방법은 자바 스크립트(JavaScript)를 사용하는 것으로 이것은 클라이언트 사이트에서 스크립트를 다운로드하여 실행 |
하이퍼텍스트 전송 프로토콜(HTTP)
첫 번째 방법은 비영속적 연결(nonpersistent connection)
두 번째 방법을 영속적 연결(persistent connection)이라 한다.
비영속적 연결
비영속적 연결(nonpersistent connection)에서는 각 요청/응답에 대해 하나의 TCP 연결이 만들어지며, 이 전략의 동작은 아래와 같음
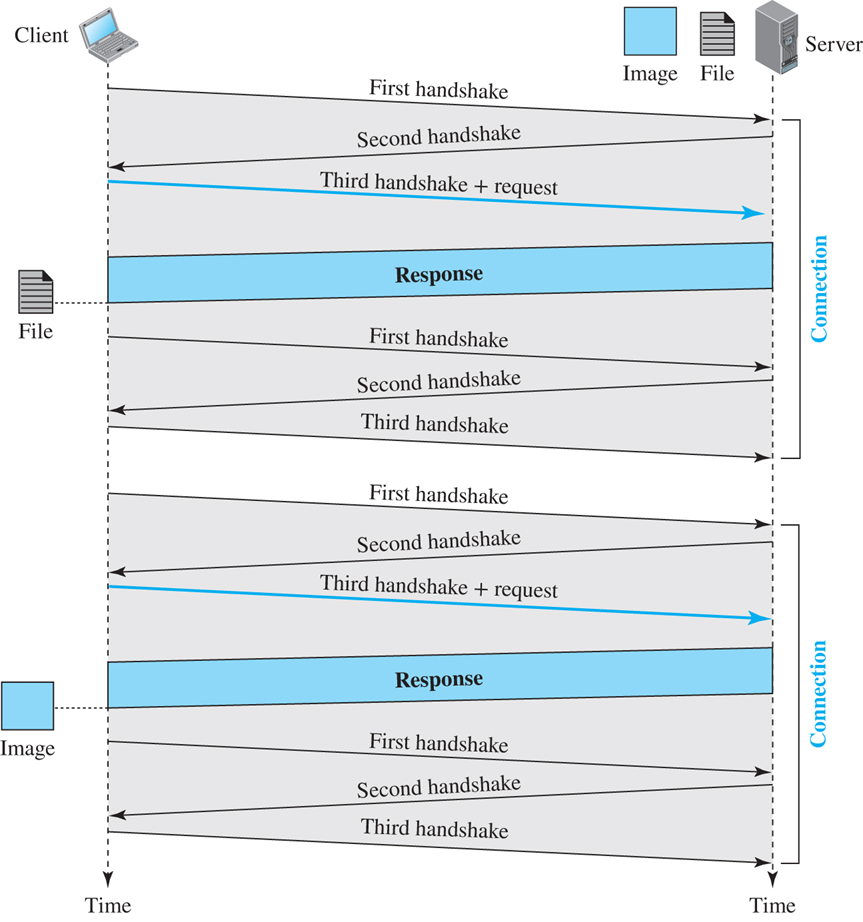
1. 클라이언트가 TCP 연결을 열고 요청을 보낸다.
2. 서버는 응답을 보내고 연결을 닫는다.
3. 클라이언트는 end-of-file 표시가 나타날 때까지 데이터를 읽고, 그 후 연결을 닫는다.
영속적 연결

| - 영속적 연결에서 서버는 응답을 전송한 후에 차후의 요청을 위해 연결을 열어 놓은 상태로 유지
- 서버는 클라이언트의 요청이 있을 때나 타임아웃이 되면 연결을 닫을 수 있음 - 송신자는 보통 각 응답으로 데이터의 길이를 송신하지만, 송신자가 데이터의 길이를 알지 못하는 경우가 때때로 있으며, 이것은 문서가 동적이거나 액티브일 때 발생 - 이 경우 서버는 데이터의 길이를 모르며, 데이터를 전송한 후 연결을 닫을 것이라고 클라이언트에게 알리고, 그 결과 클라이언트는 데이터의 끝부분에 도달했음을 인지 - 영속적 연결을 사용하면 시간과 자원을 절약할 수 있으며, 오직 하나의 버퍼와 변수만이 각 사이트의 연결을 설정하는데 필요함 - 연결 설정과 연결 종료를 위한 왕복 시간(round trip time)이 절약 |
메시지 형식
HTTP는 요청과 응답 메시지의 형식을 규정하며, 각 메시지는 4개의 구역으로 구분
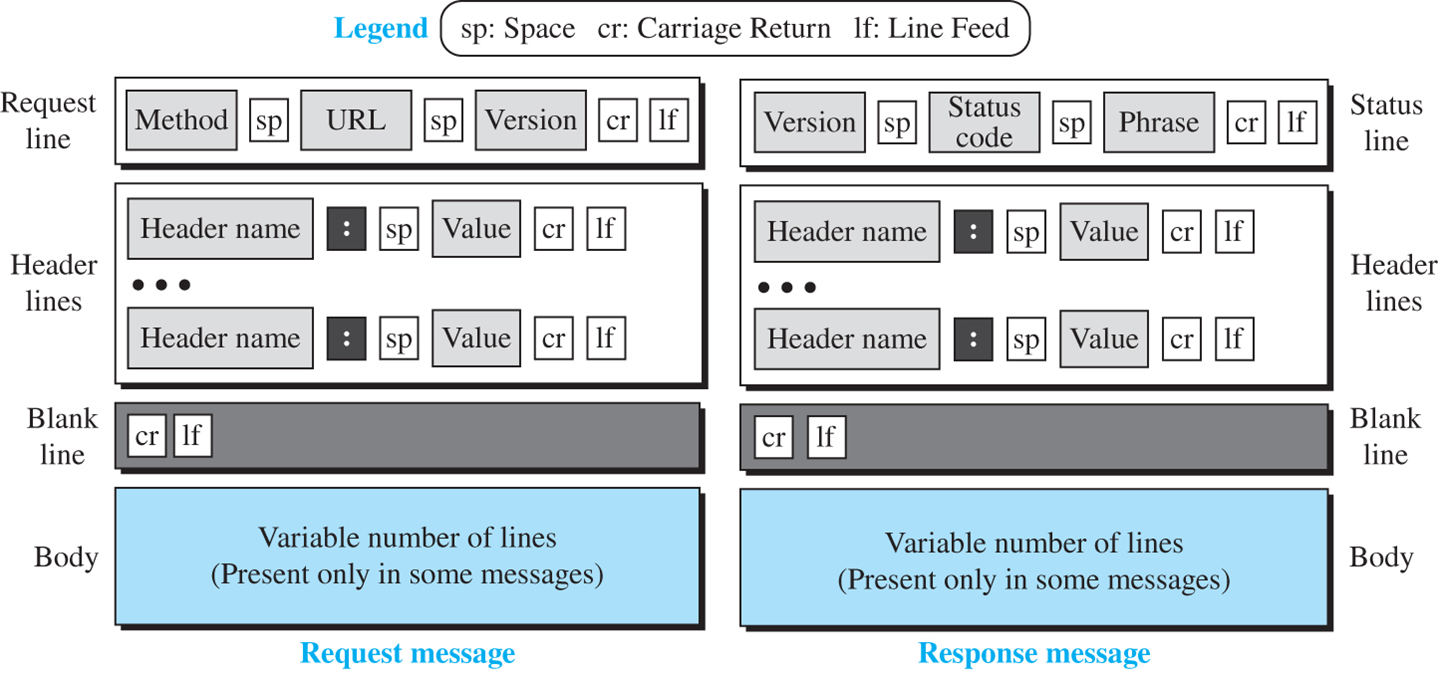
요청 메시지(Request Message)
|
- 요청 메시지의 첫 번째 라인은 요청 라인
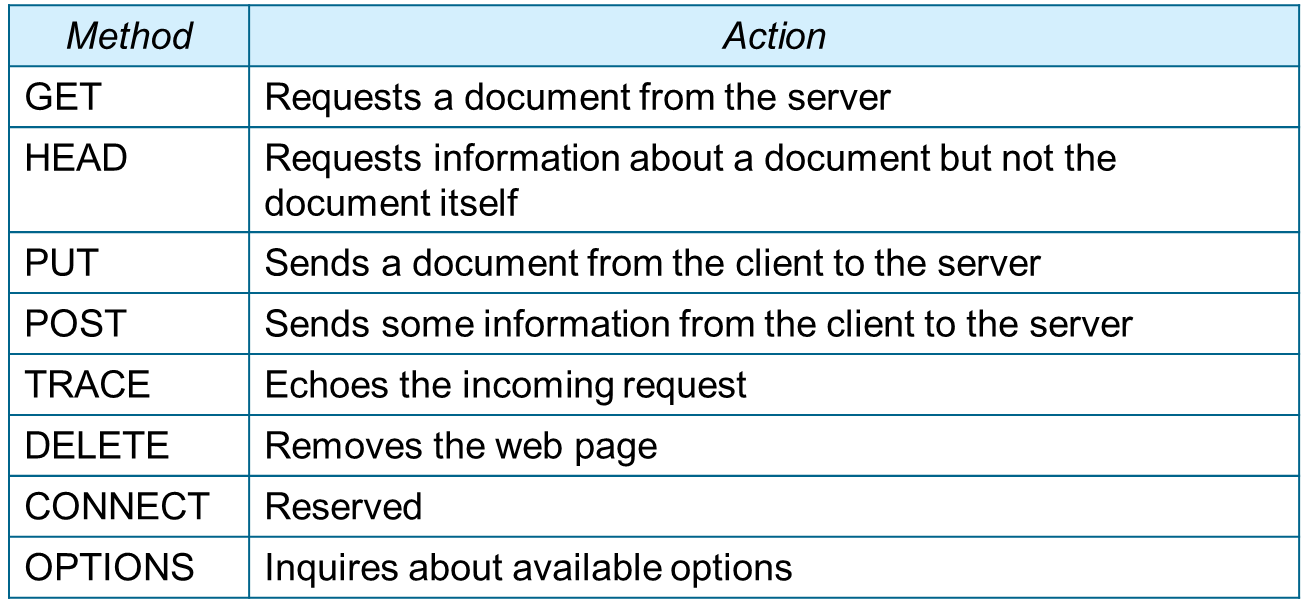
- 이 라인에는 그림과 같이 3개 필드가 있고, 각각은 하나의 스페이스로 구분되며, 2개의 문자 CR(Carrige Return)과 LF(Line Feed)로 종료 - 각 필드는 메소드(method), URL, 버전(version)이라 불림
- 메소드 필드는 요청 메시지의 유형을 정의 - HTTP 버전 1.1에서는 여러 개의 메소드가 정의 - 대부분 클라이언트는 요청 메시지를 송신할 때 GET 메소드를 사용하며, 이 경우에 메시지의 본문은 비어 있음 - HEAD 메소드는 클라이언트가 서버로부터 웹 페이지에 대한 어떤 정보(예를 들어 마지막 변경 시간 등)가 필요할 때 사용하며 또한 URL의 유효성 검사에도 사용될 수 있으며, 이 경우 응답 메시지는 본문은 비어 있고 헤더 구역만 존재 |
|
- 두 번째 필드인 URL은 상대 웹 페이지의 주소와 이름을 정의
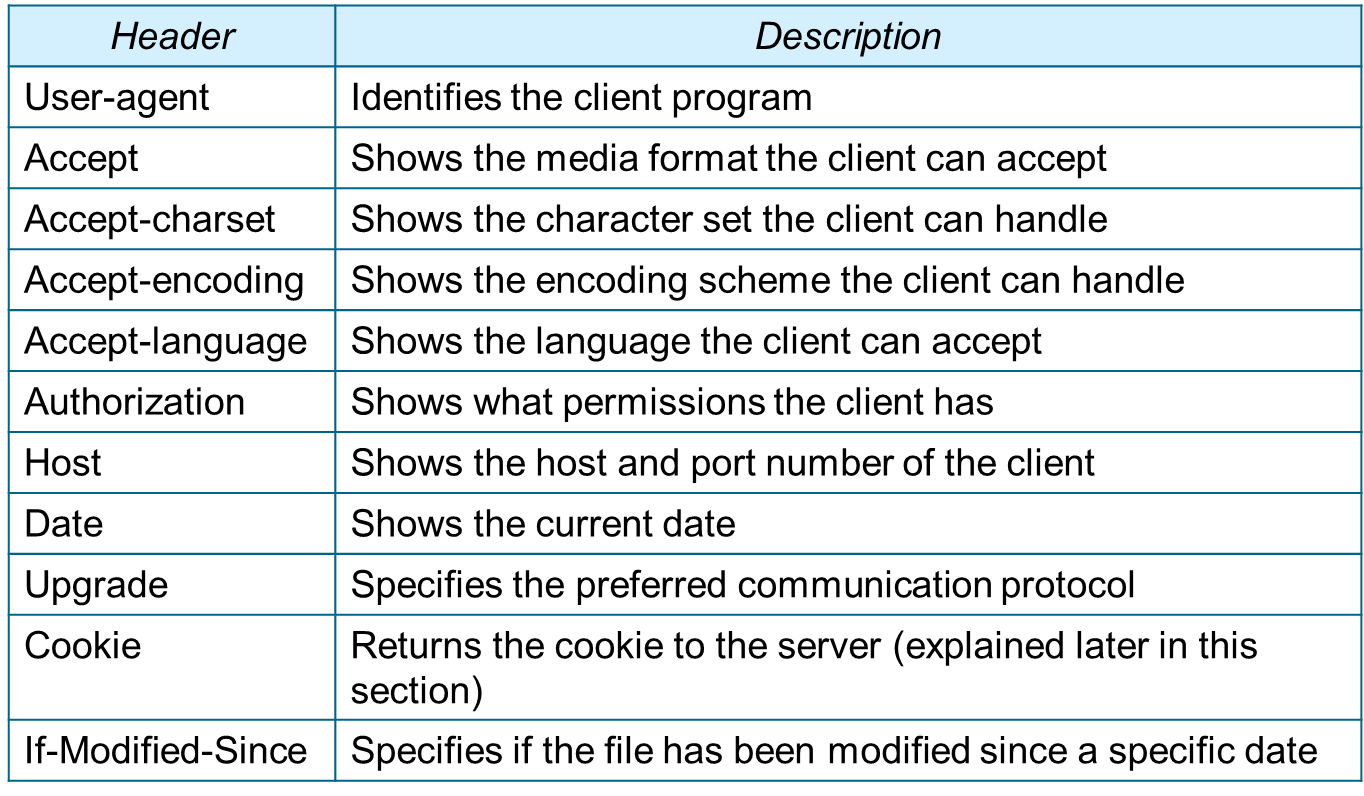
- 세 번째 필드인 버전은 프로토콜의 버전을 알려주는데, HTTP의 가장 최근 버전은 1.1이다. - 요청 라인 이후 0개 이상의 요청 헤더(request header) 라인을 가질 수 있고, 각 헤더 라인은 추가적인 정보를 클라이언트에서 서버로 보냄 |
응답 메시지(Respones Massage)
|
- 응답 메시지는 상태 라인, 헤더 라인, 공백 라인 그리고 때로 본문으로 구성
- 응답 메시지의 첫 번째 라인은 상태 라인이라 불리며, 이 라인의 3개 필드는 스페이스로 구분되어 있고, CR과 LF로 종료 - 첫 번째 필드는 HTTP 프로토콜의 버전(현재 1.1)을 규정 - 상태 코드 필드는 요청의 상태에 대해 정의하며 숫자 3개로 구성 - 100번대의 코드는 오직 정보를 제공하는 코드이지만 200번대의 코드는 성공적인 요청을 의미 - 300번대의 코드는 다른 URL로 클라이언트를 재지정(redirect)하며, 400번대의 코드는 클라이언트 사이트의 오류를 의미 - 500 범위의 코드는 서버 사이트의 오류를 의미 - 상태 문구(status phrase)는 텍스트 형태로 상태 코드를 설명 - 상태 라인 이후 응답 헤더 라인을 가질 수 있음 - 각 헤더 라인은 서버에서 클라이언트로 추가적인 정보를 보내는데, 예를 들어 송신자는 문서에 대한 부가 정보를 보낼 수 있음 - 각 헤더 라인은 헤더 이름과 콜론, 스페이스 그리고 헤더 값을 가지고 있음 - 본문은 서버로부터 클라이언트로 보내지는 문서를 포함하며, 응답은 오류 메시지가 아니라면 존재 |

쿠키
쿠키의 생성과 저장은 구현에 따라 다르나 원리는 동일
1. 서버가 클라이언트로부터 요청을 받았을 때, 클라이언트에 관한 정보를 파일이나 문자열로 저장
2. 서버는 클라이언트에게 보내는 응답에 쿠키를 포함
3. 클라이언트가 응답을 받으면, 브라우저는 도메인 서버 이름으로 정렬되는 쿠키 디렉토리에 쿠키를 저장
|
- 클라이언트가 서버에게 재요청을 보낼 때, 브라우저는 쿠키 디렉토리를 검색하여 서버가 보낸 쿠키를 검색
- 만일 있다면, 쿠키를 요청에 포함시켜서 서버가 요청을 받을 때, 서버는 이것이 새로운 것이 아닌 기존 클라이언트라는 것을 알게 됨 - 쿠키의 내용은 브라우저가 읽을 수 없거나 사용자에게 보이지 않으며, 이것이 서버가 만들고 사용하는 쿠키임 |
웹 캐싱(Web Caching): 프록시 서버
|
HTTP는 프록시 서버(proxy server)를 지원
- 프록시 서버는 최신 요청에 대한 응답들의 복사본을 갖고 있는 컴퓨터
- HTTP 클라이언트는 프록시 서버로 요청을 보내고, 프록시 서버는 캐시(cache)를 검사하여, 만일 응답이 캐시에 저장되어 있지 않으면, 프록시 서버는 대응 서버로 요청을 보냄 - 들어온 응답은 프록시 서버로 보내지고 다음에 있을 다른 클라이언트의 요청에 대비해 저장 - 프록시 서버는 원래 서버의 부하를 줄이고, 트래픽을 감소시키며, 지연을 개선 - 하지만 프록시 서버를 사용하기 위해서 클라이언트는 대상 서버(target server) 대신 프록시를 액세스하도록 설정되어야 함 - 프록시 서버는 서버와 클라이언트 양쪽으로 동작
- 프록시 서버가 캐시에 저장된(이미 가지고 있는) 요청을 받으면 프록시 서버는 서버로 동작하고, 클라이언트에 응답을 보냄 - 응답이 캐시에 없는 요청을 받으면(정보가 없으면) 프록시 서버는 먼저 클라이언트로 동작하고 요청을 대상 서버로 보냄 프록시 서버는 일반적으로 클라이언트 사이트에 위치 - 클라이언트 컴퓨터는 작은 용량으로 프록시 서버로 사용될 수 있고, 클라이언트에 의해 자주 호출되는 요청에 대한 응답을 저장
|
HTTP 보안
- HTTP 자체는 보안을 제공하지는 않지만, HTTP는 안전한 소켓 계층(SSL, Secure Socket Layer) 상에서 운영될 수 있음
'데이터 통신' 카테고리의 다른 글
| [데이터 통신과 네트워킹] 응용층(DNS) (0) | 2022.11.09 |
|---|---|
| [데이터 통신과 네트워킹] 응용층(FTP, E-mail) (0) | 2022.11.07 |
| [데이터 통신과 네트워킹] Chapter 10 응용층 기본 연습문제 풀이 (0) | 2022.11.02 |
| [데이터 통신과 네트워킹] SCTP란? (0) | 2022.10.10 |
| [데이터 통신과 네트워킹] TCP 혼잡 제어 (0) | 2022.10.07 |



